性能优化是一个开发者不可避开的话题,本文讨论iOS的性能体现在以下几个方面
- CPU占用率
- 内存占用率
- 卡顿监控/FPS
- GPU离屏渲染
- 耗电监控
- 启动时间
CPU占用率
CPU占用率是测试性能的其中一个指标,CPU作为手机最重要的组成部分,所有计算都是通过CPU进行,手机上耗电最大的应该就是CPU了,如果我们的App设计不当,会出现
Xcode可以直接看到App的内存占用,我们也可以通过系统方法获取到CPU占用率
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| #import <mach/task.h>
#import <mach/vm_map.h>
#import <mach/mach_init.h>
#import <mach/thread_act.h>
#import <mach/thread_info.h>
...
+ (double)getCpuUsage {
kern_return_t kr;
thread_array_t threadList;
mach_msg_type_number_t threadCount;
thread_info_data_t threadInfo;
mach_msg_type_number_t threadInfoCount;
thread_basic_info_t threadBasicInfo;
kr = task_threads(mach_task_self(), &threadList, &threadCount);
if (kr != KERN_SUCCESS) {
return -1;
}
double cpuUsage = 0;
for (int i = 0; i < threadCount; i++) {
threadInfoCount = THREAD_INFO_MAX;
kr = thread_info(threadList[i], THREAD_BASIC_INFO, (thread_info_t)threadInfo, &threadInfoCount);
if (kr != KERN_SUCCESS) {
return -1;
}
threadBasicInfo = (thread_basic_info_t)threadInfo;
if (!(threadBasicInfo->flags & TH_FLAGS_IDLE)) {
cpuUsage += threadBasicInfo->cpu_usage;
}
}
vm_deallocate(mach_task_self(), (vm_offset_t)threadList, threadCount * sizeof(thread_t));
return cpuUsage / (double)TH_USAGE_SCALE * 100.0;
}
|
内存占用率
常见的内存问题是内存泄露,内存只增不减,严重时,造成OOM被系统杀掉,在iOS开发中常见的是循环引用,对于大内存的对象(例如图片)在不需要的时候应该及时释放,避免内存长期占用,内存泄露还可能带来一些业务上的问题
1
2
3
4
5
6
7
8
9
| + (double)getMemoryUsage {
task_vm_info_data_t vmInfo;
mach_msg_type_number_t count = TASK_VM_INFO_COUNT;
if(task_info(mach_task_self(), TASK_VM_INFO, (task_info_t) &vmInfo, &count) == KERN_SUCCESS) {
return (double)vmInfo.phys_footprint / (1024 * 1024);
} else {
return -1.0;
}
}
|
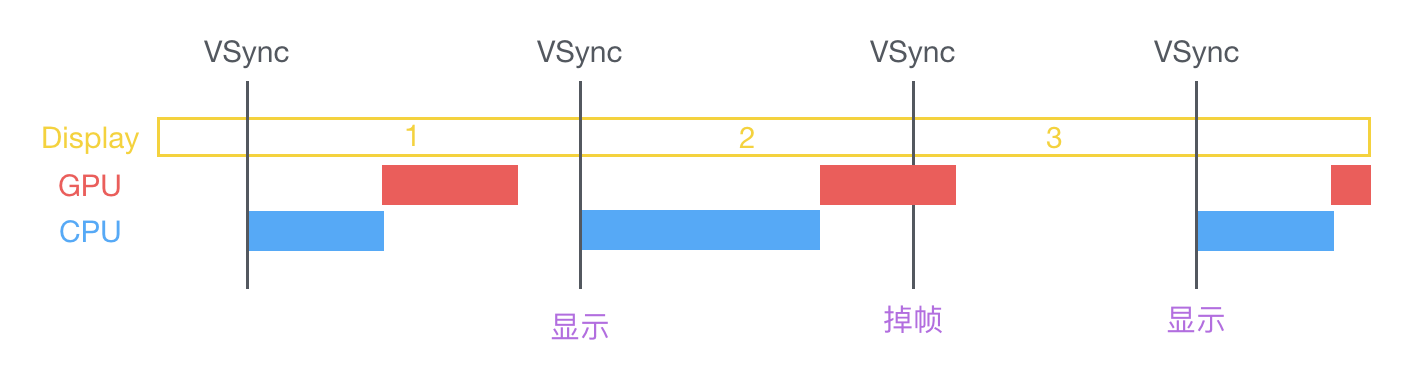
卡顿
屏幕控制器,根据屏幕刷新率,每隔一段时间就会发送一个屏幕垂直信号VSync,在VSync到来的时候
- CPU计算图层树布局,图片解码,文字渲染,然后交给GPU
- GPU渲染图层树,然后放到屏幕缓冲区上
下一个VSync到来的时候,如果CPU或GPU消耗的时间过长,GPU还来不及渲染到缓冲区中,视频控制器从屏幕缓冲区读不到数据,就会导致掉帧卡顿
FPS
FPS是卡顿的监控指标,FPS如果能稳定在50-60帧,基本可以认为是流畅的,通常我们通过CADisplayLink来监听页面刷新率,可以参考这里
1
2
3
4
|
let fps = FPS { fps in
print("当前帧率为\(fps)fps")
}
|
Runloop
FPS只是一个宏观的指标,而对于开发者来说,除了知道FPS,我们是希望定位到卡顿的位置,这个时候我们可以通过监听Runloop事件循环来实现,当发现卡顿的时候,获取主线程的调用堆栈,能获得卡顿的函数
卡顿监控还可以通过监听Runloop事件来实现,具体可以参考这里
1
2
3
4
5
|
FluencyMonitor.shared.start()
FluencyMonitor.shared.stop()
|
出现卡顿时输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| 0 libsystem_c.dylib 0x00007fff51aed510 usleep + 53
1 Demo 0x000000010fab7479 Demo.ViewController.tableView(_: __C.UITableView, cellForRowAt: Foundation.IndexPath) -> __C.UITableViewCell + 1193
2 Demo 0x000000010fab7545 @objc Demo.ViewController.tableView(_: __C.UITableView, cellForRowAt: Foundation.IndexPath) -> __C.UITableViewCell + 165
3 UIKitCore 0x00007fff48ea3f1a -[UITableView _createPreparedCellForGlobalRow:withIndexPath:willDisplay:] + 867
4 UIKitCore 0x00007fff48e6d5a6 -[UITableView _updateVisibleCellsNow:] + 3010
5 UIKitCore 0x00007fff48e8d2d2 -[UITableView layoutSubviews] + 194
6 UIKitCore 0x00007fff49193678 -[UIView(CALayerDelegate) layoutSublayersOfLayer:] + 2478
7 QuartzCore 0x00007fff2b4c6398 -[CALayer layoutSublayers] + 255
8 QuartzCore 0x00007fff2b4cc523 _ZN2CA5Layer16layout_if_neededEPNS_11TransactionE + 523
9 QuartzCore 0x00007fff2b4d7bba _ZN2CA5Layer28layout_and_display_if_neededEPNS_11TransactionE + 80
10 QuartzCore 0x00007fff2b420c04 _ZN2CA7Context18commit_transactionEPNS_11TransactionEd + 324
11 QuartzCore 0x00007fff2b4545ef _ZN2CA11Transaction6commitEv + 649
12 QuartzCore 0x00007fff2b381645 _ZN2CA7Display11DisplayLink14dispatch_itemsEyyy + 921
13 QuartzCore 0x00007fff2b4588f0 _ZL22display_timer_callbackP12__CFMachPortPvlS1_ + 299
14 CoreFoundation 0x00007fff23d6187d __CFMachPortPerform + 157
15 CoreFoundation 0x00007fff23da14e9 __CFRUNLOOP_IS_CALLING_OUT_TO_A_SOURCE1_PERFORM_FUNCTION__ + 41
16 CoreFoundation 0x00007fff23da0ae8 __CFRunLoopDoSource1 + 472
17 CoreFoundation 0x00007fff23d9b514 __CFRunLoopRun + 2228
18 CoreFoundation 0x00007fff23d9a944 CFRunLoopRunSpecific + 404
19 GraphicsServices 0x00007fff38ba6c1a GSEventRunModal + 139
20 UIKitCore 0x00007fff48c8b9ec UIApplicationMain + 1605
21 Demo 0x000000010fabaf4b main + 75
22 libdyld.dylib 0x00007fff51a231fd start + 1
|
离屏渲染(Offscreen Rrendering)
这里只讨论GPU上的离屏渲染
- 离屏渲染是屏幕缓冲区外的渲染
- GPU渲染图层是一层一层渲染的,下面的图层先渲染,上面的图层后渲染
- GPU渲染图层时,当上面的图层渲染时,不能再去修改下面图层的
- 所以当遇到superlayer依赖sublayer的时候,例如阴影(依赖sublayer的形状),就无法直接渲染到屏幕缓冲区,这个时候,GPU就会在内存中另外开辟一个缓冲区,用于渲染阴影,渲染完成后再放回到屏幕缓冲区,这个渲染操作称为离屏渲染
- GPU渲染的时候,只有一个上下文,当出现离屏渲染的时候,需要进行上下文的切换,由于上下文对象比较大,这个成本会比较高,开辟内存空间也需要消耗性能,离屏渲染多了就会导致每一帧渲染时间过长,造成卡顿
- 由于物理限制,某些场景下离屏渲染是不可避免,我们可以通过一些手段避免
在iOS上,下面操作会导致离屏渲染
- 圆角(
masksToBounds+cornerRadius),在iOS9之后,UIImageView使用masksToBounds+cornerRadius不会触发离屏渲染,其他View仍然会,避免两个属性组合使用,例如图片在内存中切好后再放到View上,对于不需要背景透明的地方,可以放一张图片罩着实现圆角
- 光栅化(
shouldRasterize):会触发离屏渲染,并且会缓存结果,避免每一帧都触发离屏渲染,可以用于优化离屏渲染
- 遮罩(
masks):尽量减少使用
- 阴影(
shadow):如果设置了shadowPath,则不会触发离屏渲染
- 抗锯齿(
allowsEdgeAntialiasing):默认关闭抗锯齿,开启会触发离屏渲染
- 组透明度(
allowsGroupOpacity): 默认开启,可以关闭来避免离屏渲染
卡顿优化
卡顿优化方向主要是减少CPU和GPU的处理时间
CPU优化
- 使用CALayer代替UIView,不用响应事件的View设置
isUserInteractionEnabled = true
- 不要频繁地修改UIView的位置,和变换属性,比如frame、bounds、transform等
- 对于复杂的布局,尽量提前计算好布局,并且使用缓存,集中计算,不要频繁改动
- Autolayout会比直接设置frame消耗更多的CPU资源,对于复杂的布局,使用frame替代autolayout
- 图片的size最好刚好跟UIImageView的size保持一致,或者不要差太多
- 减少一下线程的最大并发数量
- 尽量把耗时的操作放到子线程(文本处理,图片编解码)
GPU优化
- 尽量减少视图数量和嵌套层次
- GPU能处理的最大纹理尺寸是4096x4096,一旦超过这个尺寸,就会占用CPU资源进行处理,所以纹理尽量不要超过这个尺寸
- 尽量避免短时间内大量图片的显示,尽可能将多张图片合成一张图片显示
- 减少透明的视图(alpha<1),不透明的就设置opaque为yes,减少颜色混合操作
- 尽量避免出现离屏渲染
耗电优化
I/O
- 避免频繁的I/O操作,考虑批量操作
- 数据量比较大的局部读写,建议使用数据库,数据库对局部读写有专门的优化
- 对于读写比较大的文件数据的时候,可以考虑使用
dispatch_io,使用GCD异步并行读写,速度更快
网络
- 大文件使用断点续传,减少重复传输
- 及时
cancel掉不使用的网络请求(如当离开ViewController的时候,cancel在ViewController中产生的异步请求)
- 使用缓存,避免重复请求
- 压缩数据
定位
- 如果只是需要快速确定用户位置,用
CLLocationManager.requestLocation方法。定位完成后,会自动让定位硬件断电
- 如果不是导航应用,尽量不要实时更新位置,定位完毕就关掉定位服务
- 尽量降低定位精度,比如尽量不要使用精度最高的
kCLLocationAccuracyBest
- 需要后台定位时,尽量设置
pausesLocationUpdatesAutomatically = true,系统会根据情况自动暂停位置更新
硬件检测优化
用户移动、摇晃、倾斜设备时,会产生动作(motion)事件,这些事件由加速度计、陀螺仪、磁力计等硬件检测。在不需要检测的场合,应该及时关闭这些硬件
做到用到的时候才申请,用完就关闭
启动优化
iOS应用的启动可以分为三个阶段
dyld: 加载可执行文件,递归加载依赖库,符号绑定
- 减少动态库
- 去掉不用的类,方法和分类,减少数量
- Swift优先使用
Struct(结构体分配在栈上,不需要动态管理内存,性能优)
runtime: 初始化OC的类,category,load方法,C++静态初始化器,__attribute__((constructor))
main
- 只初始化必要的方法,能延后执行的延后执行,按需加载
- 二进制重排
参考链接